4.5 Аналіз проблем зі швидкістю роботи вебсайтів

Мета цієї статті — надати зрозумілу методику виявлення «вузьких місць» у роботі сайту на інфраструктурі TheHost. Ми почнемо з практичних вимірювань швидкості відповіді (у браузері та через консоль), а потім перейдемо до глибокої діагностики засобами CMS (на прикладі WordPress), щоб скласти пріоритетний список дій для прискорення ресурсу.
Зверніть увагу: перед початком робіт переконайтеся, що у вас є свіжі резервні копії та, за можливості, тестове середовище. Деякі режими діагностики (наприклад, SAVEQUERIES або розширене логування) збільшують витрату ресурсів і повинні включатися короткочасно та усвідомлено.
Вимірювання швидкості
Швидкість завантаження сайту — це не одне число. Щоб знайти реальне “вузьке місце”, затримки практично розділяти на два етапи:
- Час відповіді сервера (до видачі HTML): затримки на боці застосунку (PHP), повільні SQL-запити, відсутність кешування або довге очікування зовнішніх API.
- Час завантаження ресурсів (після видачі HTML): затримки на боці браузера (Frontend). Це завантаження “важких” зображень, блокуючих скриптів (JS/CSS), шрифтів і сторонніх віджетів. Цю фазу відмінно видно на графіку Network Waterfall (водоспаді запитів).
Аналіз часу відповіді сервера (TTFB)
Перший крок у будь-якій діагностиці — вимірювання TTFB (Time To First Byte). Це час від відправлення запиту до моменту, коли браузер отримує перший байт даних.
Зверніть увагу: детально про те, що це за метрика і від яких серверних факторів вона залежить, читайте в нашій статті: Що таке TTFB.
У цьому ж посібнику ми перейдемо відразу до практики: нижче ми розберемо способи вимірювання TTFB за допомогою інструментів розробника в браузері та утиліти curl, а потім за допомогою профілювання на рівні CMS (Query Monitor, логування) знайдемо конкретні важкі скрипти та запити, що уповільнюють віддачу сторінки.
Вимір TTFB у браузері
Цей метод потрібен для швидкого первинного виміру в умовах, максимально наближених до реального користувача, особливо коли немає доступу до SSH або потрібно перевірити проблему з клієнтського боку. Він показує TTFB у контексті браузера (з урахуванням DNS/TLS/маршруту і поведінки кешу), тому допомагає відокремити затримки до видачі HTML (сервер/застосунок) від проблем, що виникають уже після отримання HTML (ресурси/скрипти/фронтенд-залежності).
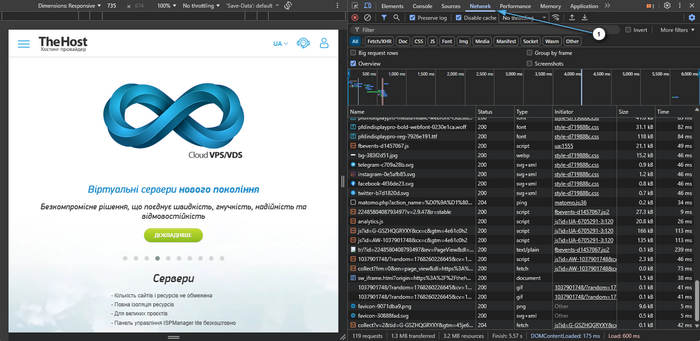
- Відкрийте сайт, який вас цікавить, у браузері. Ми рекомендуємо використовувати Google Chrome або Mozilla Firefox.
- Натисніть F12 → Network.
-
Увімкніть Disable cache (якщо доступно) й оновіть сторінку (Ctrl+R).
-
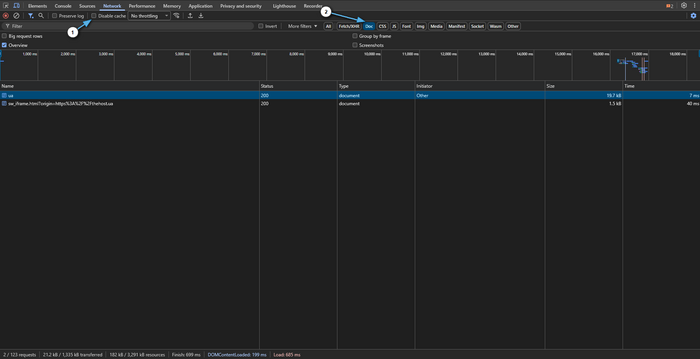
Виберіть верхній запит типу Document (HTML сторінки).
-
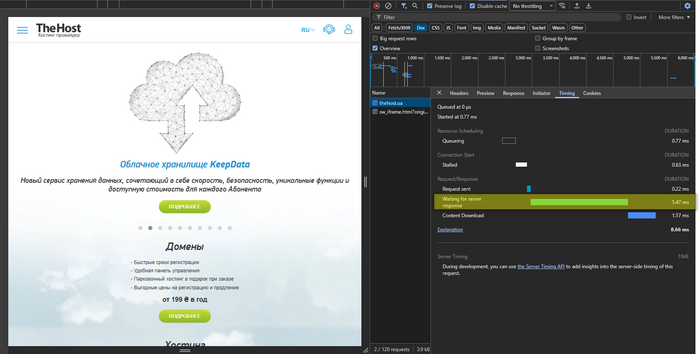
Перейдіть у вкладку Timing і дивіться:
- Waiting for server response (TTFB) — час до першого байта (аналог
time_starttransferуcurl).
- Waiting for server response (TTFB) — час до першого байта (аналог
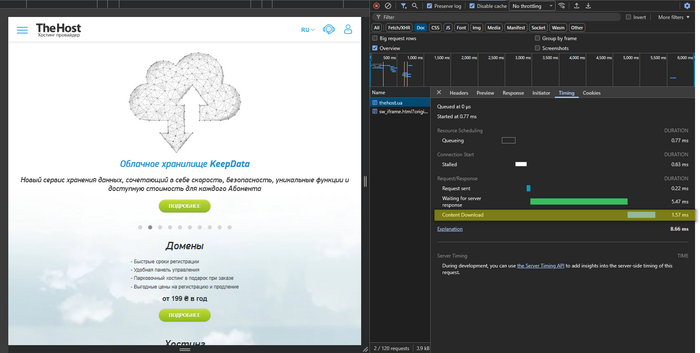
- Content Download — час завантаження вже сформованого HTML (аналог значення, що виводиться в
curl time_total, але тільки для HTML, без ресурсів сторінки).
Зверніть увагу: Орієнтири за часом
Орієнтири нижче коректніше застосовувати до простої сторінки без важкої персоналізації та за умови, що ви робите 2–3 виміри й дивитеся медіану:
- TTFB ~0.2–0.5s — зазвичай нормально.
- TTFB ~0.5–0.8s — прикордонно: залежить від навантаження, кешу та логіки сторінки.
- TTFB ~0.8–1.0s і вище — явний сигнал, що затримка формується до видачі HTML (PHP-скрипти/SQL/кеш/ресурси/зовнішні API).
Вимір TTFB за допомогою curl
Цей спосіб підійде тим, у кого є можливість запуску команд у консолі Linux або чий тарифний план послуги передбачає доступ за протоколом SSH: він дає більш “чисте” вимірювання без впливу розширень, клієнтського кешу та особливостей браузера.
curl -o /dev/null -s \
-H 'Cache-Control: no-cache' -H 'Pragma: no-cache' \
-w 'TTFB: %{time_starttransfer}\nTotal: %{time_total}\n' \
https://SITE_DOMAIN/

Що означає вивід:
- TTFB (time_starttransfer) — час до першого байта (коли відповідь почалася).
- Total (time_total) — повний час запиту (включно з отриманням усієї відповіді).
Детальний вимір швидкості сайту в браузері
Після того як HTML отримано, сторінка підвантажує ресурси (зображення, стилі, скрипти, шрифти, API-запити). Вкладка Network показує список запитів і часову шкалу, за якими видно, що саме займає час.
Для зняття виміру виконайте такі кроки:
- Відкрийте ваш сайт у браузері.
- Натисніть F12 → Network.
-
Позначте:
- Disable cache, для виміру швидкості завантаження без впливу браузерного кешу;
- за потреби Preserve log, щоб список завантажуваних ресурсів не очищався при кожному переході по сайту.
-
Оновіть сторінку за допомогою сполучення клавіш Ctrl+R. Також можна використати і сполучення Ctrl + F5.
Далі ми опишемо параметри, на які варто звернути увагу.
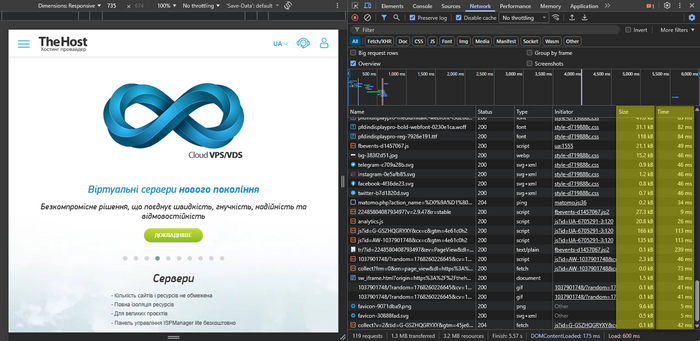
Загальна картина: який ресурс забирає найбільше часу завантаження сторінки
-
Відсортуйте вміст вкладки Network за колонками Time (Час) і Size (Розмір):
- Time — які запити займають найбільше часу.
- Size — що завантажується найбільше за обсягом передаваних мережею даних.
-
Зверніть увагу на типи:
- Img — зображення.
- JS/CSS — скрипти та стилі.
- Font — шрифти.
- XHR/Fetch — AJAX-запити.
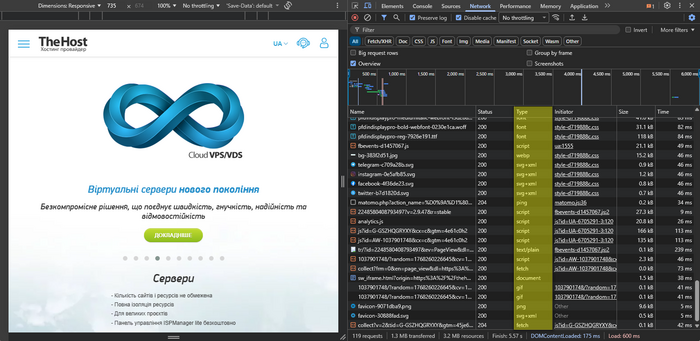
Водоспад (Waterfall): де утворюються паузи
Водоспад у DevTools Network — це часова шкала завантаження ресурсів сторінки (HTML, CSS, JS, зображення, шрифти тощо), де кожен запит показано окремою смугою з етапами очікування, встановлення з’єднання та передавання даних. За ним видно, які запити стартують рано, які — пізно, скільки вони тривають і де з’являються «вікна простою», через які сторінка відчувається повільною.
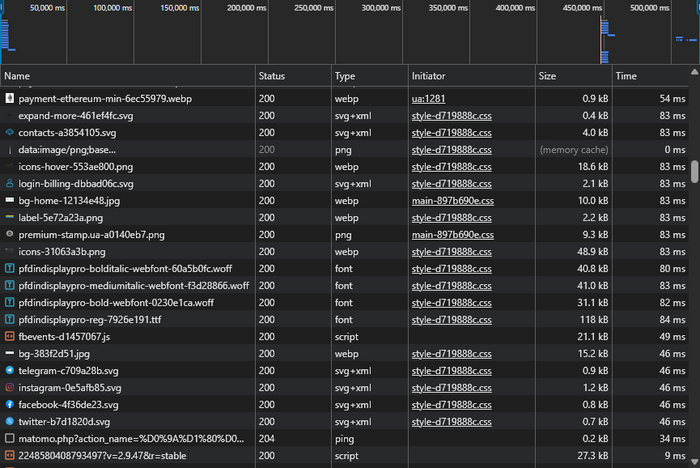
Типові ознаки:
- Довгі смуги у великих ресурсів → велика вага файлу або повільна доставка.
- Багато ресурсів стартують лише після інших → залежність завантаження (блокування, пізнє підключення).
- Довга пауза до старту більшості запитів → підвантаження починається пізно (часто через важкий JS або блокувальні ресурси).
“Ланцюжки” і блокування
Ланцюжки — це ситуації, коли один ресурс не може почати завантаження або виконання, доки не завершиться інший, наприклад, скрипт, який підтягує наступний скрипт, або стилі, без яких браузер відкладає відмальовування. Блокування — приватний випадок таких залежностей: ресурси (частіше JS/CSS або сторонні віджети) затримують критичні етапи, через що контент з’являється пізніше, навіть якщо мережа і сервер працюють нормально.
Шукайте:
- Багато JS/CSS, які завантажуються до відмальовування → затримують появу контенту.
- Сторонні домени (аналітика, чат, віджети) → часто дають помітні затримки.
- Повторювані запити або багато дрібних файлів → зростають накладні витрати на завантаження контенту.
Аналіз продуктивності засобами CMS
Важливо: аналіз продуктивності засобами CMS має сенс проводити насамперед тоді, коли TTFB стабільно підвищений — це ознака того, що затримка формується на стороні сервера під час генерації HTML (PHP-скрипти/SQL/кеш/зовнішні виклики). Також якщо гальмують XHR/Fetch (AJAX) або API-ендпоїнти, їх варто профілювати в застосунку/CMS навіть за нормального TTFB головної сторінки.
Профайлінг «усередині» CMS — це діагностика, яка показує, на що йде час під час формування сторінки: які запити до бази виконуються, які модулі/плагіни/компоненти навантажують систему, і чи є зовнішні звернення (API), які затримують відповідь.
Важливо правильно очікувати результат: профайлінг не прискорює сайт сам по собі. Він дає факти, за якими видно, що саме уповільнює генерацію сторінки і куди найвигідніше докласти зусиль.
Практична мета — знайти 1–3 ключові вузькі місця, які дають основну частку затримки і найчастіше напряму підвищують TTFB.
Щоб результати були порівнюваними, дійте як у звичайному експерименті: спочатку фіксуємо вихідні значення, потім змінюємо по одному фактору й переперевіряємо.
- Виберіть 2–4 контрольні сторінки: головна, категорія/каталог, картка товару/запису, пошук, адмінка (якщо є скарги на адмінку).
- Проведіть базові виміри: TTFB і поведінку завантаження за Network (ці кроки вже розібрані вище).
- Вмикайте режими діагностики короткочасно і фіксуйте зміни по одному: одна зміна → один повторний вимір.
Зверніть увагу: якщо ви паралельно ввімкнете debug-режим, зміните тему і оновите кілька плагінів — висновок буде нечітким: ви побачите, що щось стало працювати краще або ж гірше, але не зрозумієте, чому.
Загальні принципи аналізу для будь-якої CMS
Незалежно від платформи, профайлінг майже завжди впирається в три напрями. Їх корисно тримати в голові, тому що вони допомагають класифікувати проблему і швидше обрати наступний крок.
1) SQL-запити до бази даних
Якщо база віддає дані повільно, сторінка фізично не може сформуватися швидко.
- шукайте повільні запити (умовно: > 0.1–0.5 секунди)
- шукайте дублювані запити (класична проблема N+1)
- перевіряйте наявність індексів на часто використовуваних полях
2) Логіка застосунку (PHP/Python/інші мови)
Навіть за оптимізованої бази сайт може гальмувати через важку бізнес-логіку, обробку шаблонів, складні фільтри, генерацію блоків, імпорт даних.
- які модулі/розширення/плагіни активні
- які функції/обробники займають найбільше часу
- чи є цикли з великою кількістю ітерацій
- чи використовується кешування (page cache, object cache)
3) Зовнішні залежності
Ці затримки зазвичай плаваючі: сьогодні швидко, завтра повільно — тому що залежать від мережі й сторонніх сервісів.
- HTTP-запити до сторонніх API (платежі, аналітика, інтеграції)
- підключення до зовнішніх сервісів (CDN, пошукові індекси)
- перевірки ліцензій, оновлень, статистики
Інструменти діагностики
Далі завдання просте: знайти джерело даних, яке покаже вам SQL/час/модулі/зовнішні запити.
Вбудовані можливості CMS
Зазвичай це розділи адмінки на кшталт Performance / Developer / Debug / Maintenance. Вбудований debug-режим часто одразу показує частину запитів, час виконання і статистику по пам’яті.
Розширення і модулі
Якщо вбудованих засобів мало, майже завжди є профайлери і debug-панелі. У пошуку по каталогу розширень використовуйте слова: profiler, debug toolbar, query monitor, performance.
Логування на рівні оточення
Якщо UI-інструментів немає або вони незручні, корисні логи:
- PHP error log (налаштовується в php.ini/панелі керування)
- логи застосунку/CMS (якщо в адмінці є окремий розділ логів)
Приклад аналізу сайту на базі CMS WordPress

WordPress — одна з найпопулярніших CMS у світі, тому для неї існує велика кількість стабільних і добре документованих інструментів діагностики та оптимізації. WordPress зручний тим, що для нього є надійні інструменти, які показують SQL, хуки та зовнішні запити прямо на поточній сторінці.
Query Monitor: основний інструмент
Query Monitor — плагін, який додає панель діагностики й показує інформацію щодо поточного запиту прямо в адмінпанелі.
Насамперед перейдіть у вкладку плагінів.
Натисніть кнопку додавання плагінів.
У рядку пошуку введіть Query Monitor. Щойно пошук буде виконано, натисніть кнопку встановлення плагіна.
Спочатку відкрийте проблемну сторінку й перегляньте «три вітрини»:
- SQL-запити (Queries) — час, повторюваність, джерело (тема/плагін/функція)
- Hooks & Actions — які хуки займають найбільше часу і хто їх додав
- HTTP API calls — зовнішні запити та їхня тривалість
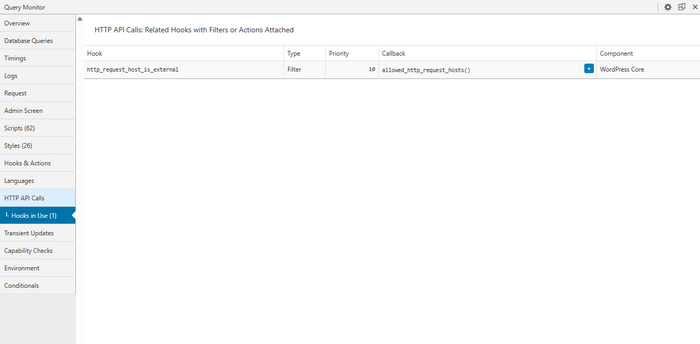
Далі важливо одразу перетворити перегляд на план:
- Випишіть 1–3 найповільніші/найчастіші SQL-запити та їхнє джерело.
- Випишіть 1–3 найдорожчі хуки або дії та хто їх додав.
- Випишіть 1–3 найповільніші зовнішні HTTP-виклики і куди вони йдуть.
- Зробіть одну зміну (плагін/налаштування/кеш) і повторіть вимір.
Діагностика без плагінів: вбудоване логування
Якщо з якихось причин встановлювати плагіни у ваш WordPress не можна, то можна короткочасно увімкнути розширене логування.
У wp-config.php на час діагностики встановіть такі значення:
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', true);
define('WP_DEBUG_DISPLAY', false);
Після цього записи логу зберігатимуться в wp-content/debug.log. Цей файл зручно використовувати як «журнал фактів», особливо якщо ви додаєте точкові error_log() поруч із проблемними місцями.
Логування SQL-запитів вмикається окремо і лише на короткий час:
define('SAVEQUERIES', true);
Важливо: SAVEQUERIES збільшує навантаження та витрати пам’яті, тому вмикайте його короткочасно, збирайте дані й вимикайте.
Замініть поточний блок секції на розширений варіант нижче (готовий до вставки). Він пояснює де додати і як використовувати.
Точковий мікропрофайлінг у коді
Якщо потрібно швидко оцінити, скільки зайняла обробка запиту загалом (без деталізації за функціями), додайте мінімальні виміри часу і запишіть результат у лог. Це зручно для порівняння «до/після»: вимкнули плагін, увімкнули кеш, змінили налаштування → оновили сторінку → порівняли час у лозі.
Нижче розглянемо два практичні способи, де розмістити цей код: через MU-plugin (краще, бо не залежить від теми) і через functions.php активної теми (швидше в налаштуванні, але менш надійно під час оновлень/зміни теми).
Варіант A (рекомендується): MU-plugin (не залежить від теми)
- Відкрийте каталог
wp-content/. - Якщо папки
mu-pluginsнемає — створітьwp-content/mu-plugins/. - Створіть файл, наприклад
wp-content/mu-plugins/request-timer.php. - Вставте код нижче. MU-плагіни підключаються автоматично, активувати в адмінці не потрібно.
<?php
add_action('init', function () {
// Логуємо тільки для адміністраторів, щоб не створювати зайве навантаження та обсяг логів
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$GLOBALS['t0'] = microtime(true);
}, 0);
add_action('shutdown', function () {
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$t = microtime(true) - ($GLOBALS['t0'] ?? microtime(true));
error_log('WP request time: ' . $t . ' uri=' . ($_SERVER['REQUEST_URI'] ?? ''));
});
?>
Варіант B: functions.php Скрипти встановленої теми
Файл: wp-content/themes/<ваша-тема>/functions.php (вставляти в кінець файла).
Мінус: під час зміни або оновлення теми правка може загубитися.
<?php
// some code...
add_action('init', function () {
// Логуємо тільки для адміністраторів, щоб не створювати зайве навантаження та обсяг логів
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$GLOBALS['t0'] = microtime(true);
}, 0);
add_action('shutdown', function () {
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$t = microtime(true) - ($GLOBALS['t0'] ?? microtime(true));
error_log('WP request time: ' . $t . ' uri=' . ($_SERVER['REQUEST_URI'] ?? ''));
});
?>
Як використовувати (процес)
- Виберіть 2–4 контрольні сторінки (головна, категорія, картка, пошук, адмінка).
- Відкрийте сторінку 2–3 рази, проведіть базові виміри, кілька разів завантаживши сторінку, що вимірюється, і отримавши середнє арифметичне на підставі записів про час її відкриття з логу.
- Внесіть одну зміну (наприклад, вимкнули конкретний плагін).
- Повторіть вимір на тих самих сторінках і порівняйте значення в лозі.
Цей вимір відображає час виконання PHP/WordPress-частини на сервері (приблизно те, що впливає на TTFB), але не включає завантаження ресурсів браузером.
Для перегляду результатів перевірте:
- Якщо ввімкнено
WP_DEBUG_LOG— файлwp-content/debug.log. - Інакше — error log PHP/веб-сервера (залежить від оточення).
Важливо: після діагностики видаліть код (або файл MU-plugin), щоб не вести зайве логування і не витрачати ресурси.
Підказка: Коли потрібні зовнішні інструменти
Якщо під час роботи CMS або вашого сайту ви бачите проблему, але не можете зрозуміти, що саме і чому призводить до її появи (наприклад, потрібен розбір за функціями/класами або глибше по базі даних), підключають зовнішні профілювальники та глибший моніторинг. Найчастіше це потребує VPS/виділеного сервера й акуратного тестування на копії.
Орієнтуйтеся за задачею:
- потрібно побачити, яка функція або метод «з’їдає» час → профілювальник рівня мови (наприклад, Xdebug/Blackfire/Tideways)
- потрібно зрозуміти, які запити і чому стали повільними → розширена діагностика бази (slow query, статистика)
- потрібно зрозуміти, чому сервер загалом гальмує → системний моніторинг (CPU/RAM/диск)
Специфіка аналізу інших популярних CMS

Нижче — орієнтири, де саме шукати вузькі місця в типових CMS і в якій послідовності це зазвичай найшвидше дає результат. Підхід універсальний: у кожній системі відрізняються назви модулів і точок входу, але логіка діагностики однакова — спочатку фіксуєте клієнтські метрики, потім підтверджуєте причини на стороні сервера та CMS. Це не сувора інструкція, а практична карта для старту, яка скорочує час на первинний аналіз і допомагає одразу виділити кандидатів на оптимізацію. Додатково враховуйте, що в різних CMS по-різному влаштовані кеш, обробка шаблонів і плагіни, тому корисно перевіряти не лише швидкість, а й умови, за яких кеш не застосовується, а також внесок розширень та інтеграцій.
Як правильно користуватися цим розділом: спочатку зафіксуйте TTFB і картину завантаження в браузері, потім вмикайте діагностику в CMS лише за ознак затримки на стороні генерації HTML (високий/нестабільний TTFB). Для порівнюваності результатів виберіть 2–4 контрольні сторінки й змінюйте один фактор за раз.
Joomla
Вбудовані інструменти
Увімкнення: System → Global Configuration → System → Debug System: YES. Після цього Joomla може показувати SQL-запити, використання пам’яті й час виконання, а також список завантажених файлів/розширень.
На що звернути увагу
- кількість і «важкість» модулів на сторінці (особливо якщо модулів багато в шаблоні)
- кешування (System → Global Configuration → System → Cache)
- стиснення та параметри кешу сторінок
Drupal
Інструменти розробника
Найчастіше використовують Devel module (query log, memory usage, execution time). Для детальної панелі — Webprofiler (частина Devel).
На що звернути увагу
- Views і їхнє кешування (часте джерело важких запитів)
- кількість активних модулів
- Twig і кеш компіляції шаблонів
OpenCart
Як підійти до діагностики
Якщо є developer/debug розширення — використовуйте його (пошук у marketplace за словами debug/profiler). Якщо розширень немає, починайте з логів помилок і точкових вимірів навколо проблемних місць.
На що звернути увагу
- кількість модулів/розширень на сторінці
- запити до товарів/категорій (часто N+1)
- сторонні модулі оплати/доставки (зовнішні HTTP-запити)
MODX, PrestaShop та інші
Для інших CMS майже завжди працює однаковий алгоритм:
- знайдіть в офіційній документації розділи debugging / performance
- перевірте маркетплейс/каталог модулів на наявність профайлерів
- увімкніть логування на рівні CMS і короткочасно зберіть дані по 2–4 проблемних сторінках
Вище ми розібрали, як перевести суб’єктивне «сайт повільний» у вимірювані факти: зафіксувати TTFB (у браузері та через curl) і за Network waterfall зрозуміти, де саме формується затримка — до видачі HTML чи після. Якщо TTFB підвищений, наступний крок — підтвердити причини на стороні застосунку/CMS (SQL, хуки/модулі, зовнішні HTTP-виклики) і отримати список конкретних кандидатів на оптимізацію. Нижче — універсальна послідовність дій, яка допомагає не розпорошуватися й швидко дійти до пріоритетних змін.
Принцип відтворюваності: фіксуйте базові виміри (2–3 виміри і медіана), потім змінюйте лише один фактор за раз і повторюйте вимірювання на тих самих контрольних сторінках. Це захищає від хибних висновків і прискорює пошук реального вузького місця.
Універсальний чек-лист для діагностики

Чек-лист допомагає пройти діагностику послідовно: від вимірювань до причин, щоб швидко виділити конкретні вузькі місця та пріоритетні дії.
Крок 1: Базові вимірювання
Спочатку зафіксуйте клієнтські метрики:
- виміряйте TTFB за допомогою браузера або
curl - перевірте послідовність завантаження ресурсів після отримання HTML (Network waterfall)
Крок 2: Увімкніть debug-режим CMS
Далі увімкніть діагностику на стороні CMS/застосунку:
- активуйте вбудований debug/developer mode або підключіть профайлер
- зберіть дані на заздалегідь вибраних контрольних сторінках
Крок 3: Сформуйте список основних джерел затримки
Переведіть проблему в конкретні кандидати:
- 3 найповільніші SQL-запити
- 3 найбільш ресурсоємні модулі/компоненти/плагіни
- зовнішні HTTP-запити (якщо є) із зазначенням тривалості
Крок 4: Перевірте кешування та причини промахів
Важливо оцінити не лише наявність кешу, а й умови, за яких він не застосовується:
- чи активний page cache
- чи активний object cache і query cache, якщо це підтримується CMS
- чи немає факторів, які призводять до частих промахів або скидань (динамічні блоки, авторизація, часті оновлення, відмінні cookie/заголовки)
Крок 5: Пріоритизація та перевірка ефекту
- починайте зі зміни з максимальним очікуваним ефектом
- після кожної зміни повторюйте вимір і порівнюйте з базовою лінією
Висновок
Тепер у вас є відтворювана база вимірювань: TTFB (через DevTools і curl) і розуміння, де формується затримка — до видачі HTML (логіка застосунку, SQL, кешування, зовнішні HTTP-виклики) чи після (ресурси сторінки, шрифти, сторонні скрипти, кількість запитів). Це переводить суб’єктивне «повільно» в конкретні показники, які можна покращувати крок за кроком і перевіряти цифрами.
Подальші дії залежать від того, який шар потребує оптимізації. Для практичних сценаріїв продовжуйте з однією зі статей:
- Аналіз продуктивності на послугах Хостингу — якщо потрібно сфокусуватися на налаштуваннях CMS, кешуванні, скороченні «важких» плагінів/модулів та оптимізації ресурсів сторінки.
- Оптимізація на послугах VPS/VDS, Dedicated — якщо ви готові заглибитися в налаштування серверного оточення (web-server, PHP-FPM, OPcache), контроль фонових задач і системний моніторинг.
- Оптимізація бази даних — якщо за результатами діагностики основний час іде в SQL: повільні запити, повторювані вибірки, індекси та блокування.
Рекомендується зберігати «базову лінію» метрик і після кожної зміни повторювати вимір: так ви підвищуєте продуктивність передбачувано і можете підтверджувати ефект вимірюваннями.

