4.5 Анализ проблем со скоростью работы веб-сайтов

Цель этой статьи — дать понятную методику выявления «узких мест» в работе сайта на инфраструктуре TheHost. Мы начнём с практических измерений скорости ответа (в браузере и через консоль), а затем перейдём к глубокой диагностике средствами CMS (на примере WordPress), чтобы составить приоритетный список действий для ускорения ресурса.
Обратите внимание: перед началом работ убедитесь, что у вас есть свежие резервные копии и, по возможности, тестовая среда. Некоторые режимы диагностики (например, SAVEQUERIES или расширенное логирование) увеличивают расход ресурсов и должны включаться кратковременно и осознанно.
Замер скорости
Скорость загрузки сайта — это не одно число. Чтобы найти реальное “узкое место”, задержки практично разделять на два этапа:
- Время ответа сервера (до выдачи HTML): задержки на стороне приложения (PHP), медленные SQL-запросы, отсутствие кэширования или долгое ожидание внешних API.
- Время загрузки ресурсов (после выдачи HTML): задержки на стороне браузера (Frontend). Это загрузка “тяжелых” изображений, блокирующих скриптов (JS/CSS), шрифтов и сторонних виджетов. Эту фазу отлично видно на графике Network Waterfall (водопаде запросов).
Анализ времени ответа сервера (TTFB)
Первый шаг в любой диагностике — замер TTFB (Time To First Byte). Это время от отправки запроса до момента, когда браузер получает первый байт данных.
Обратите внимание: подробно о том, что это за метрика и от каких серверных факторов она зависит, читайте в нашей статье: Что такое TTFB.
В этом же руководстве мы перейдем сразу к практике: ниже мы разберем способы замера TTFB с помощью инструментов разработчика в браузере и утилиты curl, а затем с помощью профилирования на уровне CMS (Query Monitor, логирование) найдем конкретные тяжелые скрипты и запросы, замедляющие отдачу страницы.
Замер TTFB в браузере
Данный метод нужен для быстрого первичного замера в условиях максимально близких к реальному пользователю, особенно когда нет доступа к SSH или требуется проверить проблему с клиентской стороны. Он показывает TTFB в контексте браузера (с учётом DNS/TLS/маршрута и поведения кэша), поэтому помогает отделить задержки до выдачи HTML (сервер/приложение) от проблем, возникающих уже после получения HTML (ресурсы/скрипты/фронтенд-зависимости).
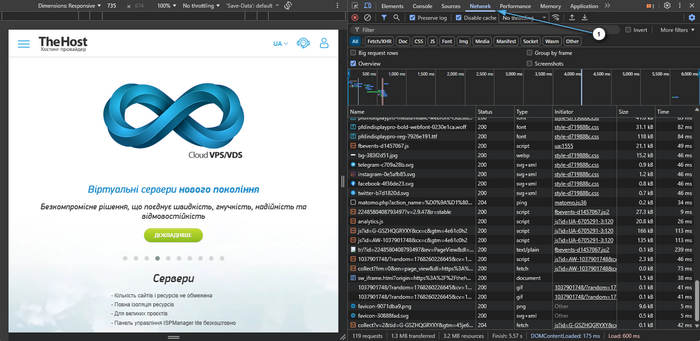
- Откройте интересующий вас сайт в браузере. Мы рекомендуем использовать Google Chrome или Mozilla Firefox.
- Нажмите F12 → Network.
-
Включите Disable cache (если доступно) и обновите страницу (Ctrl+R).
-
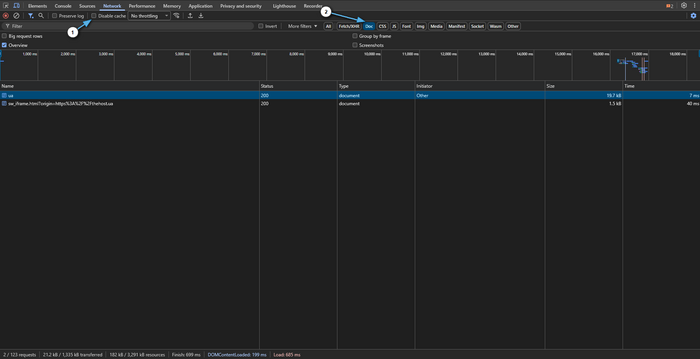
Выберите верхний запрос типа Document (HTML страницы).
-
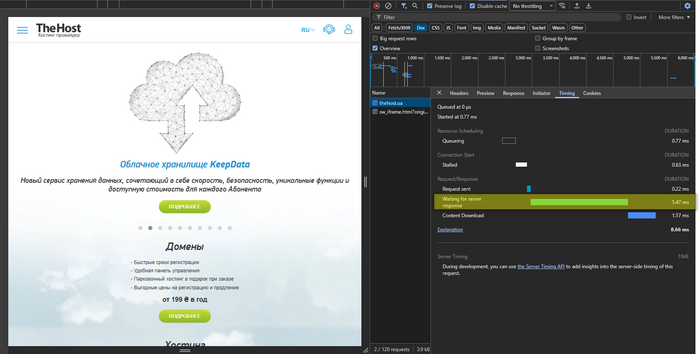
Перейдите во вкладку Timing и смотрите:
- Waiting for server response (TTFB) — время до первого байта (аналог
time_starttransferвcurl).
- Waiting for server response (TTFB) — время до первого байта (аналог
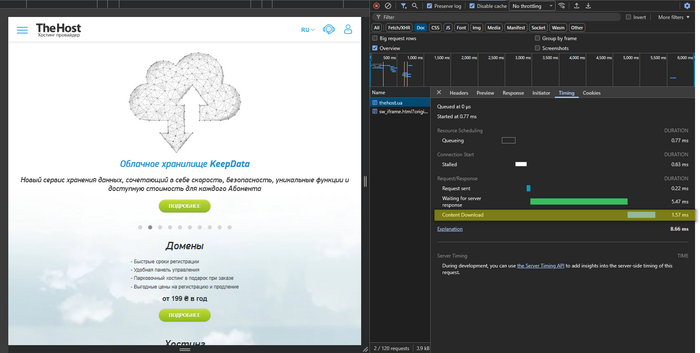
- Content Download — время скачивания уже сформированного HTML (аналог значения, выводимого в
curl time_total, но только для HTML, без ресурсов страницы).
Обратите внимание: Ориентиры по времени
Ориентиры ниже корректнее применять к простой странице без тяжёлой персонализации и при условии, что вы делаете 2–3 замера и смотрите медиану:
- TTFB ~0.2–0.5s — обычно нормально.
- TTFB ~0.5–0.8s — погранично: зависит от нагрузки, кэша и логики страницы.
- TTFB ~0.8–1.0s и выше — явный сигнал, что задержка формируется до выдачи HTML (PHP скрипты/SQL/кэш/ресурсы/внешние API).
Замер TTFB с помощью curl
Данный способ подойдёт тем, у кого есть возможность запуска команд в консоли Linux или чей тарифный план услуги предусматривает доступ по протоколу SSH: он даёт более “чистое” измерение без влияния расширений, клиентского кэша и особенностей браузера.
curl -o /dev/null -s \
-H 'Cache-Control: no-cache' -H 'Pragma: no-cache' \
-w 'TTFB: %{time_starttransfer}\nTotal: %{time_total}\n' \
https://SITE_DOMAIN/

Что означает вывод:
- TTFB (time_starttransfer) — время до первого байта (когда ответ начался).
- Total (time_total) — полное время запроса (включая получение всего ответа).
Подробный замер скорости сайта в браузере
После того как HTML получен, страница подгружает ресурсы (изображения, стили, скрипты, шрифты, API-запросы). Вкладка Network показывает список запросов и временную шкалу, по которым видно, что именно занимает время.
Для снятия замера выполните следующие шаги:
- Откройте Ваш сайт в браузере.
- Нажмите F12 → Network.
- Отметьте:
- Disable cache, для замера скорости загрузки без влияния браузерного кэша;
- при необходимости Preserve log, чтобы список загружаемых ресурсов не очищался при каждом переходе по сайту.
- Обновите страницу с помощью сочетания клавиш Ctrl+R. Также можно использовать сочетание Ctrl + F5.
Далее мы опишем параметры, на которые стоит обратить внимание.
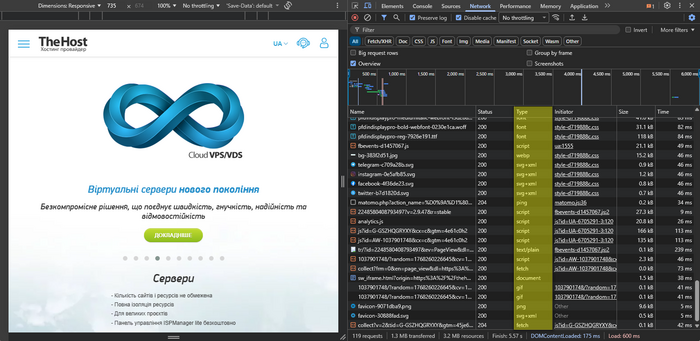
Общая картина: какой ресурс отнимает больше всего времени загрузки страницы
- Отсортируйте содержимое вкладки Network по колонкам Time (Время) и Size (Размер):
- Time — какие запросы занимают больше всего времени.
- Size — что грузится больше всего по объёму передаваемых по сети данных.
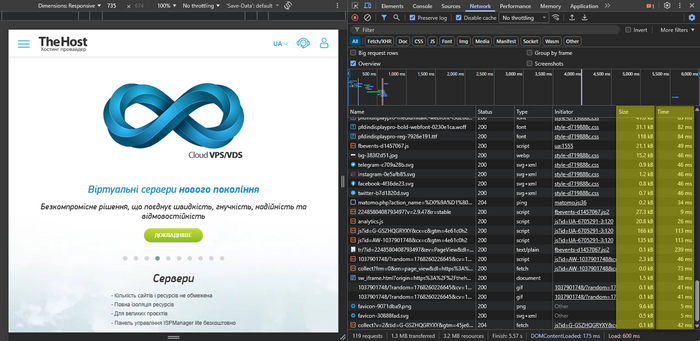
- Обратите внимание на типы:
- Img — изображения.
- JS/CSS — скрипты и стили.
- Font — шрифты.
- XHR/Fetch — AJAX-запросы.
Водопад (Waterfall): где образуются паузы
Водопад в DevTools Network — это временная шкала загрузки ресурсов страницы (HTML, CSS, JS, изображения, шрифты и т.д.), где каждый запрос показан отдельной полосой с этапами ожидания, установления соединения и передачи данных. По нему видно, какие запросы стартуют рано, какие — поздно, сколько они длятся и где появляются «окна простоя», из-за которых страница ощущается медленной.
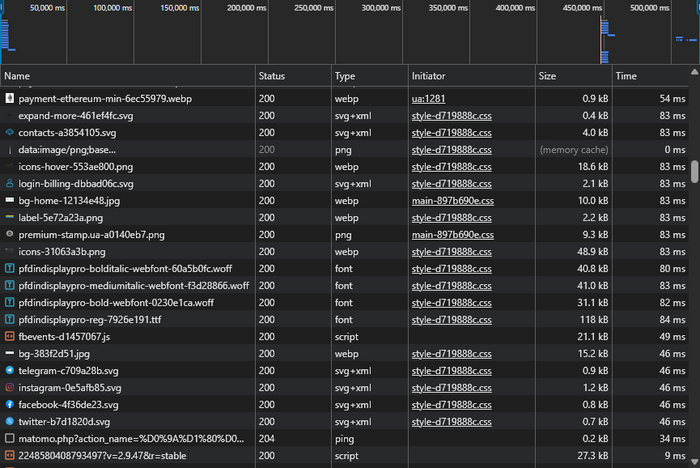
Типовые признаки:
- Длинные полосы у крупных ресурсов → большой вес файла или медленная доставка.
- Многие ресурсы стартуют только после других → зависимость загрузки (блокировки, позднее подключение).
- Длинная пауза до старта большинства запросов → подгрузка начинается поздно (часто из-за тяжёлого JS или блокирующих ресурсов).
“Цепочки” и блокировки
Цепочки — это ситуации, когда один ресурс не может начать загрузку или выполнение, пока не завершится другой, например, скрипт, который подтягивает следующий скрипт, или стили, без которых браузер откладывает отрисовку. Блокировки — частный случай таких зависимостей: ресурсы (чаще JS/CSS или сторонние виджеты) задерживают критические этапы, из-за чего контент появляется позже, даже если сеть и сервер работают нормально.
Ищите:
- Много JS/CSS, которые загружаются до отрисовки → задерживают появление контента.
- Сторонние домены (аналитика, чат, виджеты) → часто дают заметные задержки.
- Повторяющиеся запросы или много мелких файлов → растут накладные расходы на скачивание контента.
Анализ производительности средствами CMS
Важно: анализ производительности средствами CMS имеет смысл проводить в первую очередь тогда, когда TTFB стабильно повышен — это признак того, что задержка формируется на стороне сервера при генерации HTML (PHP-скрипты/SQL/кэш/внешние вызовы). Также если тормозят XHR/Fetch (AJAX) или API-эндпоинты, их стоит профилировать в приложении/CMS даже при нормальном TTFB главной страницы.
Профайлинг «внутри» CMS — это диагностика, которая показывает, на что уходит время при формировании страницы: какие запросы к базе выполняются, какие модули/плагины/компоненты нагружают систему, и есть ли внешние обращения (API), которые задерживают ответ.
Важно правильно ожидать результат: профайлинг не ускоряет сайт сам по себе. Он даёт факты, по которым видно, что именно замедляет генерацию страницы и куда выгоднее всего приложить усилия.
Практическая цель — найти 1–3 ключевых узких места, которые дают основную долю задержки и чаще всего напрямую повышают TTFB.
Чтобы результаты были сравнимыми, действуйте как при обычном эксперименте: сначала фиксируем исходные значения, затем меняем по одному фактору и перепроверяем.
- Выберите 2–4 контрольные страницы: главная, категория/каталог, карточка товара/записи, поиск, админка (если жалобы на админку).
- Проведите базовые замеры: TTFB и поведение загрузки по Network (эти шаги уже разобраны выше).
- Включайте режимы диагностики кратковременно и фиксируйте изменения по одному: одно изменение → один повторный замер.
Обратите внимание: если Вы параллельно включите debug-режим, поменяете тему и обновите несколько плагинов — вывод будет нечётким: вы увидите, что что-то стало работать лучше или же хуже, но не поймёте, почему.
Общие принципы анализа для любой CMS
Независимо от платформы, профайлинг почти всегда упирается в три направления. Их полезно держать в голове, потому что они помогают классифицировать проблему и быстрее выбрать следующий шаг.
1) SQL-запросы к базе данных
Если база отдаёт данные медленно, страница физически не может сформироваться быстро.
- ищите медленные запросы (условно: > 0.1–0.5 секунды)
- ищите дублирующиеся запросы (классическая N+1 проблема)
- проверяйте наличие индексов на часто используемых полях
2) Логика приложения (PHP/Python/другие языки)
Даже при оптимизированной базе сайт может тормозить из-за тяжёлой бизнес-логики, обработки шаблонов, сложных фильтров, генерации блоков, импорта данных.
- какие модули/расширения/плагины активны
- какие функции/обработчики занимают больше всего времени
- есть ли циклы с большим количеством итераций
- используется ли кэширование (page cache, object cache)
3) Внешние зависимости
Эти задержки обычно плавающие: сегодня быстро, завтра медленно — потому что зависят от сети и сторонних сервисов.
- HTTP-запросы к сторонним API (платежи, аналитика, интеграции)
- подключение к внешним сервисам (CDN, поисковые индексы)
- проверки лицензий, обновлений, статистики
Инструменты диагностики
Дальше задача простая: найти источник данных, который покажет вам SQL/время/модули/внешние запросы.
Встроенные возможности CMS
Обычно это разделы админки вида Performance / Developer / Debug / Maintenance. Встроенный debug-режим часто сразу показывает часть запросов, время выполнения и статистику по памяти.
Расширения и модули
Если встроенных средств мало, почти всегда есть профайлеры и debug-панели. В поиске по каталогу расширений используйте слова: profiler, debug toolbar, query monitor, performance.
Логирование на уровне окружения
Если UI-инструментов нет или они неудобны, полезны логи:
- PHP error log (настраивается в php.ini/панели управления)
- логи приложения/CMS (если в админке есть отдельный раздел логов)
Пример анализа сайта на базе CMS WordPress

WordPress — одна из самых популярных CMS в мире, поэтому для неё существует большое количество стабильных и хорошо документированных инструментов диагностики и оптимизации. WordPress удобен тем, что для него есть надёжные инструменты, которые показывают SQL, хуки и внешние запросы прямо по текущей странице.
Query Monitor: основной инструмент
Query Monitor — плагин, который добавляет панель диагностики и показывает информацию по текущему запросу прямо в админ-панели.
Первым делом перейдите во вкладку плагинов.
Нажмите кнопку добавления плагинов.
В поисковой строке введите Query Monitor. Как только поиск будет выполнен, нажмите кнопку установки плагина.
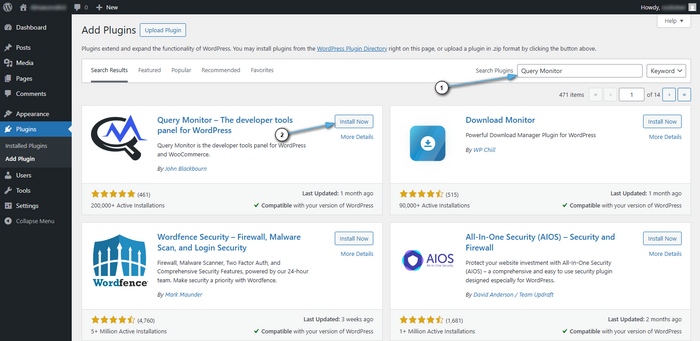
Сначала откройте проблемную страницу и посмотрите «три витрины»:
- SQL-запросы (Queries) — время, повторяемость, источник (тема/плагин/функция)
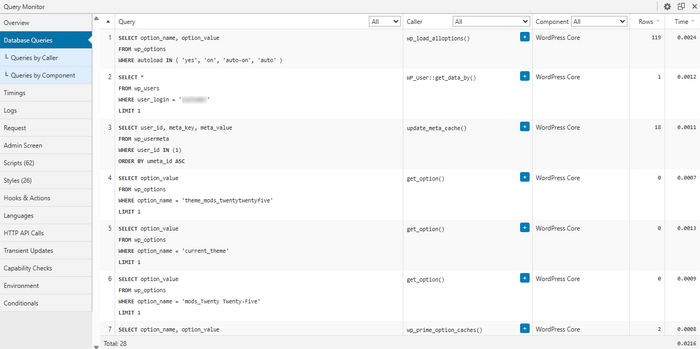
- Hooks & Actions — какие хуки занимают больше всего времени и кто их добавил
- HTTP API calls — внешние запросы и их длительность
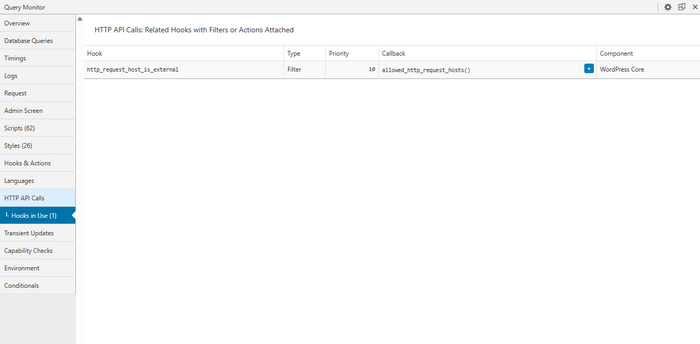
Дальше важно сразу превратить просмотр в план:
- Выпишите 1–3 самых медленных/частых SQL-запроса и их источник.
- Выпишите 1–3 самых дорогих хука или действия и кто их добавил.
- Выпишите 1–3 самых медленных внешних HTTP-вызова и куда они идут.
- Сделайте одно изменение (плагин/настройка/кэш) и повторите замер.
Диагностика без плагинов: встроенное логирование
Если по каким-то причинам устанавливать плагины в вашем WordPress нельзя, то можно кратковременно включить расширенное логирование.
В wp-config.php на время диагностики установите следующие значения:
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', true);
define('WP_DEBUG_DISPLAY', false);
После этого записи лога будут сохраняться в wp-content/debug.log. Этот файл удобно использовать как «журнал фактов», особенно если вы добавляете точечные error_log() рядом с проблемными местами.
Логирование SQL-запросов включается отдельно и только на короткое время:
define('SAVEQUERIES', true);
Важно: SAVEQUERIES увеличивает нагрузку и расход памяти, поэтому включайте его кратковременно, собирайте данные и отключайте.
Замените текущий блок секции на расширенный вариант ниже (готов к вставке). Он объясняет где добавить и как использовать.
Точечный микро-профайлинг в коде
Если нужно быстро оценить, сколько заняла обработка запроса в целом (без детализации по функциям), добавьте минимальные замеры времени и запишите результат в лог. Это удобно для сравнения «до/после»: отключили плагин, включили кэш, поменяли настройку → обновили страницу → сравнили времена в логе.
Ниже рассмотрим два практичных способа, где разместить этот код: через MU-plugin (предпочтительно, так как не зависит от темы) и через functions.php активной темы (быстрее в установке, но менее надёжно при обновлениях/смене темы).
Вариант A (рекомендуется): MU-plugin (не зависит от темы)
- Откройте каталог
wp-content/. - Если папки
mu-pluginsнет — создайтеwp-content/mu-plugins/. - Создайте файл, например
wp-content/mu-plugins/request-timer.php. - Вставьте код ниже. MU-плагины подключаются автоматически, активировать в админке не нужно.
<?php
add_action('init', function () {
// Логируем только для админов, чтобы не создавать лишнюю нагрузку и объём логов
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$GLOBALS['t0'] = microtime(true);
}, 0);
add_action('shutdown', function () {
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$t = microtime(true) - ($GLOBALS['t0'] ?? microtime(true));
error_log('WP request time: ' . $t . ' uri=' . ($_SERVER['REQUEST_URI'] ?? ''));
});
?>
Вариант B: functions.php Скрипты установленной темы
Файл: wp-content/themes/<ваша-тема>/functions.php (вставлять в конец файла).
Минус: при смене или обновлении темы правка может потеряться.
<?php
// some code...
add_action('init', function () {
// Логируем только для админов, чтобы не создавать лишнюю нагрузку и объём логов
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$GLOBALS['t0'] = microtime(true);
}, 0);
add_action('shutdown', function () {
if (!is_user_logged_in() || !current_user_can('manage_options')) {
return;
}
$t = microtime(true) - ($GLOBALS['t0'] ?? microtime(true));
error_log('WP request time: ' . $t . ' uri=' . ($_SERVER['REQUEST_URI'] ?? ''));
});
?>
Как использовать (процесс)
- Выберите 2–4 контрольные страницы (главная, категория, карточка, поиск, админка).
- Откройте страницу 2–3 раза, проведите базовые замеры, несколько раз загрузив замеряемую страницу и получив среднее арифметическое на основании записей о времени её открытия из лога.
- Внесите одно изменение (например, отключили конкретный плагин).
- Повторите замер на тех же страницах и сравните значения в логе.
Этот замер отражает время выполнения PHP/WordPress-части на сервере (примерно то, что влияет на TTFB), но не включает загрузку ресурсов браузером.
Для просмотра результатов проверьте:
- Если включено
WP_DEBUG_LOG— файлwp-content/debug.log. - Иначе — error log PHP/веб-сервера (зависит от окружения).
Важно: после диагностики удалите код (или файл MU-plugin), чтобы не вести лишнее логирование и не расходовать ресурсы.
Подсказка: Когда нужны внешние инструменты
Если при работе CMS или Вашего сайта вы видите проблему, но не можете понять что именно и почему приводит к её появлению (например, нужен разбор по функциям/классам или глубже по базе данных), подключают внешние профилировщики и более глубокий мониторинг. Чаще всего это требует VPS/выделенного сервера и аккуратного тестирования на копии.
Ориентируйтесь по задаче:
- нужно увидеть, какая функция или метод съедает время → профилировщик уровня языка (например, Xdebug/Blackfire/Tideways)
- нужно понять, какие запросы и почему стали медленными → расширенная диагностика базы (slow query, статистика)
- нужно понять, почему сервер в целом тормозит → системный мониторинг (CPU/RAM/диск)
Специфика анализа других популярных CMS

Ниже — ориентиры, где именно искать узкие места в типовых CMS и в какой последовательности это обычно быстрее всего даёт результат. Подход универсален: в каждой системе отличаются названия модулей и точек входа, но логика диагностики одинаковая — сначала фиксируете клиентские метрики, затем подтверждаете причины на стороне сервера и CMS. Это не строгая инструкция, а практичная карта для старта, которая сокращает время на первичный анализ и помогает сразу выделить кандидатов на оптимизацию. Дополнительно учитывайте, что в разных CMS по-разному устроены кэш, обработка шаблонов и плагины, поэтому полезно проверять не только скорость, но и условия, при которых кэш не применяется, а также вклад расширений и интеграций.
Как правильно пользоваться этим разделом: сначала зафиксируйте TTFB и картину загрузки в браузере, затем включайте диагностику в CMS только при признаках задержки на стороне генерации HTML (высокий/нестабильный TTFB). Для сравнимости результатов выберите 2–4 контрольные страницы и меняйте один фактор за раз.
Joomla
Встроенные инструменты
Включение: System → Global Configuration → System → Debug System: YES. После этого Joomla может показывать SQL-запросы, использование памяти и время выполнения, а также список загруженных файлов/расширений.
На что обратить внимание
- количество и тяжесть модулей на странице (особенно если модулей много в шаблоне)
- кэширование (System → Global Configuration → System → Cache)
- сжатие и параметры кэша страниц
Drupal
Инструменты разработчика
Чаще всего используют Devel module (query log, memory usage, execution time). Для детальной панели — Webprofiler (часть Devel).
На что обратить внимание
- Views и их кэширование (частый источник тяжёлых запросов)
- количество активных модулей
- Twig и кэш компиляции шаблонов
OpenCart
Как подойти к диагностике
Если есть developer/debug расширение — используйте его (поиск в marketplace по словам debug/profiler). Если расширений нет, начинайте с логов ошибок и точечных замеров вокруг проблемных мест.
На что обратить внимание
- количество модулей/расширений на странице
- запросы к товарам/категориям (часто N+1)
- сторонние модули оплаты/доставки (внешние HTTP-запросы)
MODX, PrestaShop и другие
Для остальных CMS почти всегда работает одинаковый алгоритм:
- найдите в официальной документации разделы debugging / performance
- проверьте маркетплейс/каталог модулей на наличие профайлеров
- включите логирование на уровне CMS и кратковременно соберите данные по 2–4 проблемным страницам
Выше мы разобрали, как перевести субъективное «сайт медленный» в измеряемые факты: зафиксировать TTFB (в браузере и через curl) и по Network waterfall понять, где именно формируется задержка — до выдачи HTML или после. Если TTFB повышен, следующий шаг — подтвердить причины на стороне приложения/CMS (SQL, хуки/модули, внешние HTTP-вызовы) и получить список конкретных кандидатов на оптимизацию. Ниже — универсальная последовательность действий, которая помогает не распыляться и быстро дойти до приоритетных изменений.
Принцип воспроизводимости: фиксируйте базовые замеры (2–3 замера и медиана), затем меняйте только один фактор за раз и повторяйте измерение на тех же контрольных страницах. Это защищает от ложных выводов и ускоряет поиск реального узкого места.
Универсальный чек-лист для диагностики

Чек-лист помогает пройти диагностику последовательно: от измерений к причинам, чтобы быстро выделить конкретные узкие места и приоритетные действия.
Шаг 1: Базовые измерения
Сначала зафиксируйте клиентские метрики:
- замерьте TTFB с помощью браузера или
curl - проверьте последовательность загрузки ресурсов после получения HTML (Network waterfall)
Шаг 2: Включите debug-режим CMS
Далее включите диагностику на стороне CMS/приложения:
- активируйте встроенный debug/developer mode или подключите профайлер
- соберите данные на заранее выбранных контрольных страницах
Шаг 3: Сформируйте список основных источников задержки
Переведите проблему в конкретные кандидаты:
- 3 самых медленных SQL-запроса
- 3 самых ресурсоёмких модуля/компонента/плагина
- внешние HTTP-запросы (если есть) с указанием длительности
Шаг 4: Проверьте кэширование и причины промахов
Важно оценить не только наличие кэша, но и условия, при которых он не применяется:
- активен ли page cache
- активен ли object cache и query cache, если это поддерживается CMS
- нет ли факторов, которые приводят к частым промахам или сбросам (динамические блоки, авторизация, частые обновления, различающиеся cookie/заголовки)
Шаг 5: Приоритизация и проверка эффекта
- начинайте с изменения с максимальным ожидаемым эффектом
- после каждого изменения повторяйте замер и сравнивайте с базовой линией
Заключение
Теперь у вас есть воспроизводимая база измерений: TTFB (через DevTools и curl) и понимание, где формируется задержка — до выдачи HTML (логика приложения, SQL, кэширование, внешние HTTP-вызовы) или после (ресурсы страницы, шрифты, сторонние скрипты, количество запросов). Это переводит субъективное «медленно» в конкретные показатели, которые можно улучшать по шагам и проверять цифрами.
Дальнейшие действия зависят от того, какой слой требует оптимизации. Для практических сценариев продолжайте с одной из статей:
- Оптимизация производительности на услугах Хостинга — если нужно сфокусироваться на настройках CMS, кэшировании, сокращении «тяжёлых» плагинов/модулей и оптимизации ресурсов страницы.
- Оптимизация на услугах VPS/VDS, Dedicated — если вы готовы углубиться в настройку серверного окружения (web-server, PHP-FPM, OPcache), контроль фоновых задач и системный мониторинг.
- Оптимизация Базы данных — если по результатам диагностики основное время уходит в SQL: медленные запросы, повторяющиеся выборки, индексы и блокировки.
Рекомендуется сохранять «базовую линию» метрик и после каждого изменения повторять замер: так вы повышаете производительность предсказуемо и можете подтверждать эффект измерениями.

